Flink 作为一个基于内存的分布式计算引擎,其内存管理模块很大程度上决定了系统的效率和稳定性,尤其对于实时流式计算,JVM GC 带来的微小延迟也有可能被业务感知到。针对这个问题,Flink 实现了一套较为优雅的内存管理机制,可以在引入小量访问成本的情况下提高内存的使用效率并显著降低 GC 成本和 OOM 风险,令用户可以通过少量的简单配置即可建立一个健壮的数据处理系统。
大数据时代的 JVM
众所周知,以 Hadoop 为核心的开源大数据生技术栈组件绝大多数运行在 JVM 之上,而为了性能考虑越来越多的后起之秀选择将数据存储到内存(比如 Spark、HBase、Drill,当然还有 Flink ),常常是一个进程占用十几GB甚至上百GB内存,这就触及并突出了 JVM 在 heap 内存管理上的几个短板:
- 潜在的 OOM 风险。在有大量对象被创建和清理的情况下,监控 JVM heap 内存的使用并不是一件轻松的事情,稍有不慎可能会触发 OOM 错误导致进程崩溃。
- GC 成本高,调优困难。Java 垃圾回收器普遍会将 heap 分为 young 和 old 两个区并基于新生代区存放短期对象、老年代区存放长期对象的假设来分别实施不同的 GC 策略。然而各区的比例是启发性和基于经验估计的,对于有数十 GB 甚至上百 GB 并伴随着大量新生对象的 JVM 来说,新生对象可能会溢出到老年代,这可能导致 GC 成本消耗50%甚至更高的性能。虽然垃圾回收器提供数十个参数给用户进行调优,然而并没有静态的参数可以完美适应运行时动态的负载。
- 对象的存储密度低。Java 对象的 header、padding 都需要占用额外的空间,在存储大量小对象的情况下尤其低效。
针对这些问题的解决方案根据组件不同有所差异,不过核心思想是一致的:在 JVM 堆内或堆外实现显式的内存管理,即用自定义内存池来进行内存块的分配和回收,并将对象序列化后存储到内存块,比如 Spark 的 Project Tungsten 和 HBase 的 BlockCache。因为内存可以被精准地申请和释放,而且序列化的数据占用的空间可以被精确计算,所以组件可以对内存有更好的掌控,这种内存管理方式也被认为是相比 Java 更像 C 语言化的做法。
Flink 的内存管理也并不例外,采用了显式的内存管理并用序列化方式存储对象,同时支持 on-heap 和 off-heap。在这点上 Flink 与 Spark 的MEMORY_ONLY_SER存储级别十分相似,不同点在于 Spark 仍以 on-heap 对象存储为主,而 Flink 则只支持序列化的对象存储。
Flink 内存管理概览
Flink 内存主要指 TaskManager 运行时提供的内存资源。TaskManager 主要由几个内部组件构成: 负责和 JobManager 等进程通信的 actor 系统,负责在内存不足时将数据溢写到磁盘和读回的 IOManager,还有负责内存管理的 MemoryManager。其中 actor 系统和 MemoryManager 会要求大量的内存。相应地,Flink 将 TaskManager 的运行时 JVM heap 分为 Network Buffers、MemoryManager 和 Free 三个区域(在 streaming 模式下只存在 Network Buffers 和 Free 两个区域,因为算子不需要缓存一次读入的大量数据)。
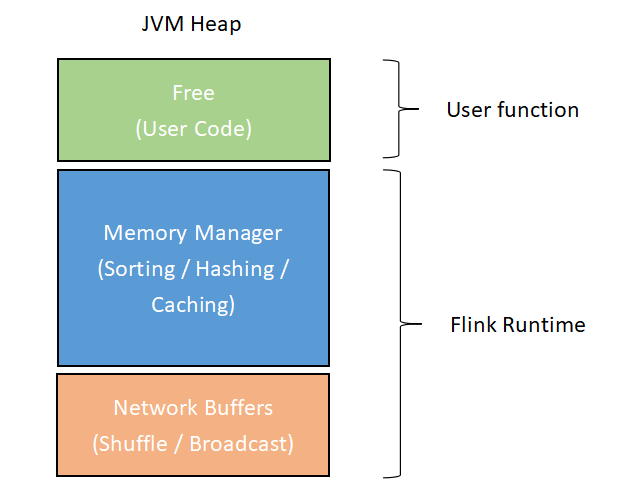
各个区域的功能如下:
- Network Buffers 区: 网络模块用于网络传输的一组缓存块对象,单个缓存块对象默认是32KB大小。Flink 会根据 TaskManager 的最大内存来计算该区大小,默认范围是64MB至1GB。
- Memory Manager 区: 用于为算子缓存运行时消息记录的大缓存池(比如 Sort、Join 这类耗费大量内存的操作),消息记录会被序列化之后存进这些缓存块对象。这部分区域默认占最大 heap 内存减去 Network Buffers 后的70%,单个缓存块同样默认是32KB。
- Free 区: 除去上述两个区域的内存剩余部分便是 Free heap,这个区域用于存放用户代码所产生的数据结构,比如用户定义的 State。
目前 Memory Manager 的内存初始化方式有两种: 第一种是启动时即为 Network Buffers 区和 MemoryManager 区分配全部内存,这样 TaskManager 启动过程中会产生一次到多次的 full GC,导致 TaskManager 的启动慢一点,但是节省了后续执行作业时的 GC 时长。第二种方式是采用”懒分配”的方法,在内存紧张时再增量向操作系统申请内存,避免一下吃完所有的内存导致后续的其他操作内存不足,例如流计算作业的 StateBackend 保存在内存的 State 对象。
Network Buffers 和 MemoryManager 的存在会贯穿 TaskManager 的整个生命周期。它们管理的 Memory Segment 不断被重用,因此不会被 JVM 回收。经过若干次 GC 之后它们会进入老年代,变成常驻的对象。
Memory Segment
Memory Segment 是 Flink 内存管理的核心概念,是在 JVM 内存上的进一步抽象(包括 on-heap 和 off-heap),代表了 Flink Managed Memory 分配的单元。每个 Memory Segment 默认占32KB,支持存储和访问不同类型的数据,包括 long、int、byte、数组等。你可以将 Memory Segment 想象为 Flink 版本的 java.nio.ByteBuffer。
不管消息数据实际存储在 on-heap 还在是 off-heap,Flink 都会将它序列化成为一个或多个的 Memory Segment(内部又称 page)。系统可能会在其他的数据结构里存指向条消息的指针(一条消息通常会被构造成一个 Memory Segment 的集合),这意味着 Flink 需要依赖于一个有 page 概念并支持跨 page 消息的高效率序列化器。因此 Flink 实现了自己的类型信息系统(Type Information System)和序列化栈。
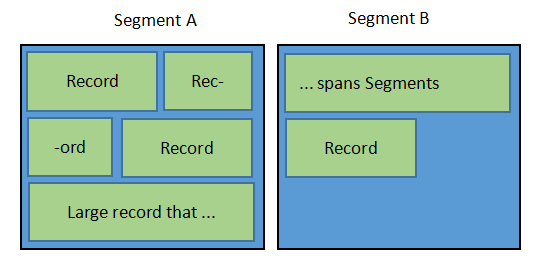
序列化的格式由 Flink 序列化器定义,并且可以描述到消息记录的单个字段,这意味着 Flink 只需要序列化目标字段而不是整个对象。这点非常重要,因为 Flink 的输入数据是以序列化方式存储的,在访问时需要反序列化,这在减小了存储空间的同时会带来一定的计算开销,所以提升序列化和反序列化(SerDe)效率可以明显提高整体性能。
熟悉 Spark 的同学看到这里可能会联想到 Spark 的 Catalyst,它可以通过运行时编译来生成 Java bytecode 并提供了直接访问二进制对象字段的能力。然而 Flink 的开发语言是 Java,不便利用 Scala 的 quasiquotes 特性,因此 Flink 采用的办法是使用定制化的序列化机制和类型系统。
Flink 序列化机制 & 类型信息系统
Java 生态圈实际上已经有不少出色的序列化库,包括 Kryo、Apache Avro、Apache Thrift 和 Google 的 ProtoBuf,然而 Flink 毅然重新造了一套轮子以定制数据的二进制格式。这带来了三点重要的优势:其一,掌握了对序列化后的数据结构信息,使得二进制数据间的比较甚至于直接操作二进制数据成为可能;其二,Flink 依据计划要执行的操作来提前优化序列化结构,极大地提高了性能;其三,Flink 可以在作业执行之前确定对象的类型,并在序列化时利用这个信息进行优化。
Flink 作业可以处理任意 Java 或 Scala 对象类型的数据。要对作业执行计划进行优化,首先要识别出作业数据流的每一个步骤的数据类型。对于 Java 程序,Flink 实现了基于反射的类型提取器来分析用户定义函数的返回类型;对于 Scala 程序,Flink 可以直接利用 Scala 编译器的类型推导特性。其后 Flink 会用TypeInformation作为类型描述符来表示每种数据类型。
Flink 类型系统存下以下内建分类:
- 基础类型: 所有 Java 原始类型和它们的包装类型(包括 Hadoop Writable 类型),加上
void、String、Date、BigDecimal和BigInteger。 - 原始类型的数组和对象数组。
- 复合类型:
- Flink Java Tuple (Flink Java API 的一部分): 最多支持25个字段,不支持 null 字段。
- Scala case classe (包括 Scala 元组): 最多支持22个字段,不支持 null 字段。
- Row: Flink API 对象,代表任意数量字段的元组,支持 null 字段。
- POJO: 遵循 Java Bean 模式的类。
- 辅助类型:
Option、Either、Lists、Maps等等。 - 通用类型: 不能被识别为以上任意类型的数据类型。Flink 不会自己序列化这些类型,而是交由 Kyro 序列化。
每个数据类型都会有专属的序列化器。举个例子,BasicTypeInfo(基础类型)的序列化器为TypeSerializer<T>,用于序列化 T 原始类型的数据;WritableTypeInfo(Hadoop Writable类型)的序列化器为WritableSerializer<T>,用于序列化实现类 Writable 接口的 T 类型的数据。
其中比较特别的是GenericTypeInfo,作为后备计划的它会委托 Kyro 进行序列化。
对象序列化后会写到 DataOutput (由 MemorySegement 所支持),并高效地自动通过 Java 的 Unsafe API 操作写到内存。对于作为 key 的数据类型,TypeInformation还会提供类型比较器(TypeComparator)。类型比较器负责对对象进行哈希和比较,取决于具体的数据类型还可以高效地比较二进制形式的对象和提取固定长度的 key 前缀。
复合类型的对象可能包含内嵌的数据类型,在这种情况下,它们的序列化器和类型比较器同样是复合的。它们会将内嵌类型的序列化和比较大小任务委托给对应类型的序列化器和类型比较器。下图描述了一个典型的复合类型对象Tuple<Integer, Double, Person>是如何序列化和存储的:
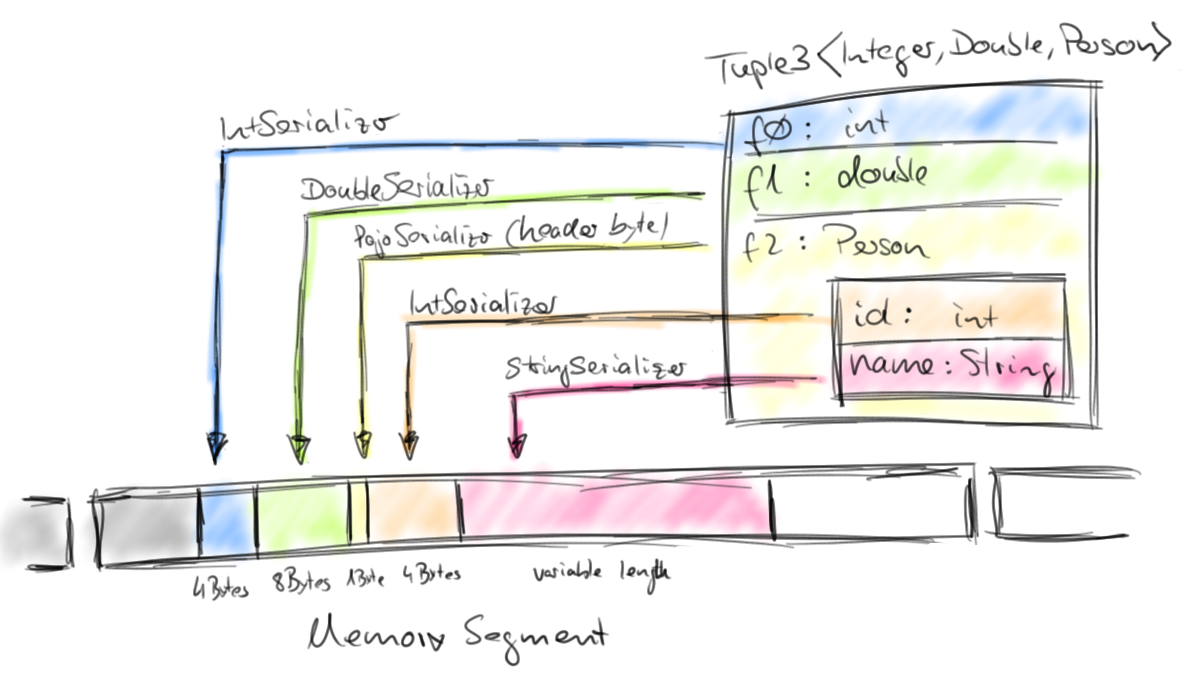
可以看出序列化后的对象存储是非常紧凑的,POJO 首部序列化后仅占1字节的空间,String 这种不固定长度的对象也以实际长度来存储。如同上文所讲,一个对象并不要求完整地存放在一个 MemorySegment 内,而是可以跨 MemorySegment 存放,这意味着将不会有内存碎片产生。
最后,如果内建的数据类型和序列化方式不能满足你的需求,Flink 的类型信息系统也支持用户拓展。用户只需要实现TypeInformation、TypeSerializer和TypeComparator即可定制自己类型的序列化和比较大小方式。
对 GC 的影响
作为简单回顾,Flink 不会将消息记录当作对象直接放到 heap 上,而是序列化后存在长期缓存对象里。这意味着将不会出现低效的短期对象,消息对象只用来在用户函数内传递和被序列化。而长期对象是 MemorySegment 本身,它们并不会被 GC 清理。
因此在 JVM 内存结构规划上,Flink 也作了相应的调整: MemoryManager 和 Network Buffers 两个实现了显式内存管理的子系统分配到老年代,而留给用户代码的 Free 区域分配到新生代,见下图。
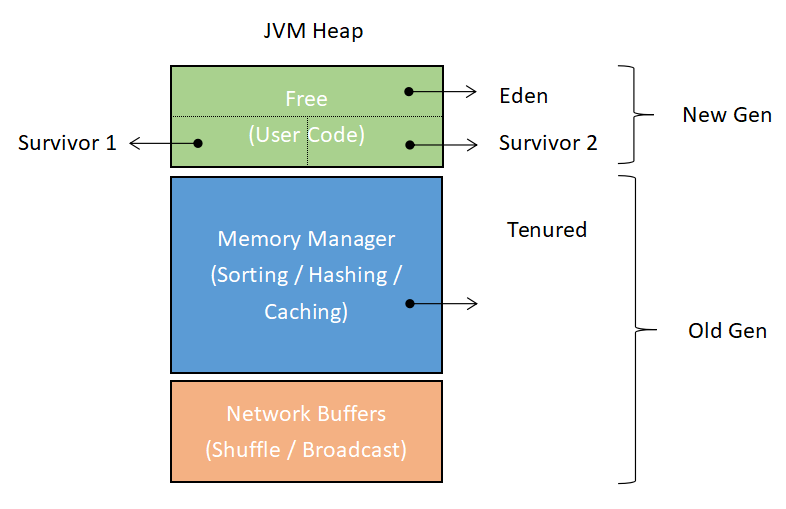
JVM 参数中控制新生代和老年代比例的参数是-XX:NewRatio,这表示了老年代空间与新生代空间之比,默认为2,即(不计Meta区)新生代占 heap 的三分之一,老年代占 heap 的三分之二。
为了证明 Flink 内存管理和序列化器的优势,Flink 官方对 Object-on-Heap (直接 Java 对象存储)、Flink-Serialized (内建序列化器 + 显式内存管理)和 Kryo-Serialized (Kryo 序列化器 + 显式内存管理)三种方案进行了 GC 表现的对比测试。
测试方法是对一千万个 Tuple2<Integer, String> 对象进行排序,其中 Integer 字段的值是均匀分布的,String 字段是长度为12的字符串并服从长尾分布。测试的作业跑在 heap 为900MB的 JVM 内,这恰好是排序一千万个对象所需要的最低内存。
测试在 JVM GC 上的表现如下图:
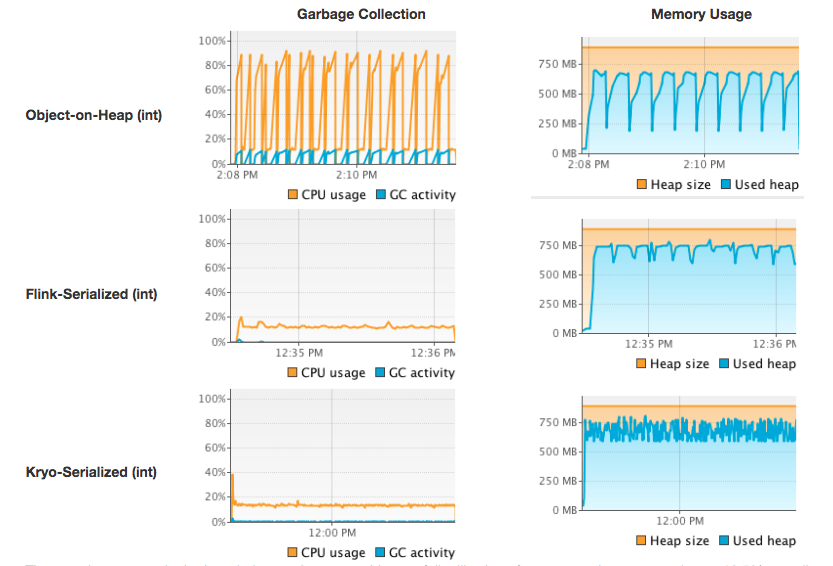
显而易见,使用显式内存管理可以显著地减少 GC 频率。在 Object-on-Heap 的测试中,GC 频繁地被触发并导致 CPU 峰值达到90%。在测试中使用的8核机器上单线程的作业最多只占用12.5%的 CPU ,机器花费在 GC 的成本显然超过了实际运行作业的成本。而在另外两个依赖显式内存管理和序列化的测试中,GC 很少被触发,CPU 使用率也一直稳定在较低的水平。
总结
Flink 在内存管理上较大程度上借鉴了 Spark 的方案,包括存储不足时的溢写机制和内存区域的划分。不过 Flink 的管理粒度更细更精确,最为典型的一点是 Spark 的序列化存储是以 RDD 的一个 Partiton 为单位,而 Flink 的序列化则是以消息记录为单位,这也体现了两者最大的区别: Spark 的哲学是将 Streaming 视作 Batch 的特例 (micro batch) ,相反地,Flink 的哲学是将 Batch 视作 Streaming 的特例。
参考文献
1.Juggling-with-Bits-and-Bytes
2.Memory Management (Batch API)
3.flinks-typeinformation-class
4.Flink 原理与实现:内存管理
5.Apache Spark 内存管理详解
6.HBase BlockCache系列 – 走进BlockCache