The Dataflow Model 是 Google Research 于2015年发表的一篇流式处理领域的有指导性意义的论文,它对数据集特征和相应的计算方式进行了归纳总结,并针对大规模/无边界/乱序数据集,提出一种可以平衡准确性/延迟/处理成本的数据模型。这篇论文的目的不在于解决目前流计算引擎无法解决的问题,而是提供一个灵活的通用数据模型,可以无缝地切合不同的应用场景。
CLC 与 CAP 定理
CAP 定理一直是设计分布式系统首要考虑的问题之一,而在流式处理领域 CAP 有了新的拓展,即 Correctness (准确性),Latency (延迟),Cost (成本),本文将其简称 CLC 。CLC 与 CAP 最大的不同点在于 CAP 的网络分区发生在系统内,而 CLC 则是发生在系统与外部环境,其余特征十分相似,有着紧密的内在联系。
Correctness 对应 CAP 定理的 Consistence 。如果说分布式存储的 Consistence 表示的是不同副本达到完全一致状态的时间窗口,Correctness 则是在固定的时间窗口内接受到的数据及其计算结果的正确程度(是否乱序,是否完整)。两者看起来似乎并没有很强的联系,但其实两者都是因为数据网络延迟而造成的系统状态落后于真实状态。不同点在于 Consistence 面向的数据源通常是分布式系统的内部节点,而 Correctness 面向的是系统外部的数据源,状态更加不可控。比如前者可以设置超时参数来控制数据的延迟在一个合理的范围,但后者由于数据源在系统外,可能会接受到严重滞后的数据,比如一个用户在野外游玩时的数据在其设备连上网络时一次性发送给服务器。
Latency 对应 CAP 定理的 Availability 。由于实时数据流是无边界的,我们不能假设在某个时间点数据会变得完整,更不能一直等待到那个时刻,因为实时数据流的价值就在于实时性,那时我们的计算结果将一文不值。因此普遍的做法是将实时数据流切分为一个个时间窗口,每当窗口关闭的时候计算一次结果。一个关键的选择便是窗口关闭的算法,还有由此带来的(也是这里所关心的)延迟。因为在一个窗口活跃期间,数据仍被视为可变的不能用于计算,所以也可以被视为不可用。这与CAP定理的 Availability 显然十分相似,不同点在于由于时间窗口是周期性的正常活动,并不需要像CAP定理一样将不可用场景视为故障。
Cost 对应 CAP 定理的 Partition Tolerance 。Cost 指的是对于延迟数据的处理带来的额外成本,延迟的定义是事件对应的时间窗口已经关闭,需要修正历史计算结果。类似分布式系统出现网络分区,流处理系统和数据源也会出现网络不可达的情况,具体表现为数据延迟。不同点在于并没有很好的办法来处理 Partition ,而数据延迟是可以处理的,关键在于处理成本上,比如要重算多久的数据。因此对于一个确定的可接受的延迟成本(Cost),“延迟容忍性”也是确定的。
逻辑引擎设计
无论是流式计算/微批次或是批处理,它们要处理的问题都可以抽象为以下几个问题:
- What: 需要计算的结果数据是什么
- Where: 计算的上下文环境是什么
- When: 什么时候计算输出结果
- How: 如何修正早期计算结果
针对这些问题,The Dataflow Model 分别提出了 windowing model , triggering model 和 incremental processing model 。值得注意的是,这些模型并不依赖物理引擎的具体实现,以允许系统设计者结合自己需求灵活集成其中的思想,以及在CLC三者中寻找平衡。
核心原语
常见的数据处理函数可以分为聚合函数与非聚合函数两大类。对于非聚合函数,每条数据都是独立的,计算引擎只需将它转换为下游需求的格式即可。而聚合类函数只能作用于有界数据集,所以我们需要将实时数据流切分为多个窗口(经常还伴随着分组),然后才可以将聚合函数应用到其上。
在 The Dataflow Model 论文中,计算引擎提供两个原语,ParDo和GroupByKey。ParDo负责执行用户函数,对数据流进行非聚合类的转换。如果Pardo作用于无边界数据集,那么它的输出仍是无边界数据集。而GroupByKey负责将数据进行分组,它会将所有相同key的数据收集到一起,然后再发至下游。显然由于缓存数据的特性,它会将无边界数据转换为有边界数据,但是它没办到单独做到这点,还需要和window函数配合使用。
通过核心原语,用户可以较为自由地描述计算过程,解答了What的问题。
窗口策略模型
除了常见的滑动窗口/翻滚窗口/会话窗口的分类,该论文提出了校准窗口与非校准窗口的区别,定义了基础的窗口操作以及如何基于这些操作来实现不同的Windowing策略。
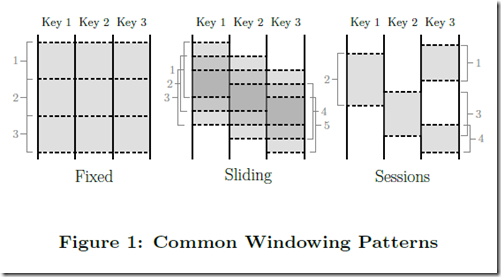
校准窗口指的是落在窗口对应时间范围内的所有数据都被用于该窗口的计算,比如金融市场常见的“前一天交易量”。而非校准窗口指的是只有落在窗口相应时间范围的数据的某一子集用于该窗口的计算,比如只计算某个key的数据。常见的窗口中,翻滚窗口和滑动窗口都属于校准窗口,而会话窗口属于非校准窗口,因为不同key的会话是独立的,只有时间相近且key相同的事件会落入同一会话窗口。
该论文在原语上提供了GroupByKey,支持聚合的系统经常会将其重新定义为粒度更细的GroupByByAndWindow。而论文中的操作实现对非校准窗口的支持,者包含了两个关键的观点: 一是从模型简化的角度上,把所有的窗口策略都当做非对齐窗口,而底层实现来负责把对齐窗口作为一个特例进行优化;二是窗口操作可以被分隔为assignWindows和mergeWindows两个相关的操作。
assignWindows即为事件分配对于的窗口。细心的同学可以发现这里的Window是复数,是不是意味着可以为一个事件分配多个窗口?事实上的确如此,这里的分配操作更像是复制到窗口里,因此如果分配给多个窗口则会产生冗余。
mergeWindows即对多个窗口进行合并,通常的使用场景是滑动窗口(校准窗口)间的合并和会话窗口(非校准窗口)间的合并。
Windowing 策略描述了事件处理的上下文,即Where的问题。
触发器和增量处理
流式计算引擎的难题之一在于知道何时关闭窗口并计算出结果发往下游。由于事件是无序的,我们无法获得一个明确的标识表示窗口对于的数据已经完全达到,这被称为窗口的完整性问题。最基础的方案是使用水位线(watermark)来解决,即根据一定算法根据最近处理的事件的事件时间估算出一个称为水位线的时间(比如最近 5 min 到达的事件的最小事件时间),早于该时间的事情被视为已经完全被处理。然而水位线是启发式的,并不能完全避免迟到的事件,另外水位线也可能引入额外的延迟。
因此只凭水位线来保证窗口完整性是不够的,论文借鉴了 Lambda 架构的思想来规避完整性问题。Lambda 架构由 Storm 的作者 Nathan Marz 提出,其核心思想是融合离线计算和在线计算以提供高可用性和最终一致性。

Lambda 架构包含三个核心 view: batch view ,real time view 和 query view。batch view 存放较早前(一般是数小时以前)的完整数据的离线计算结果;real time view 存放的是未进入 batch view 的数据的计算结果,这部分会随着新数据到来而频繁更新;query view 负责处理查询,合并 batch view 和 real time view 的结果输出。
Lambda 架构有高可用,低延迟和高容错的优点 ,但不足也显然易见: 需要开发和维护两条数据处理管道。
针对这个问题 The Dataflow Model 论文引入了触发器机制来简化 Lambda 架构,以合并两条数据处理管道。
简单来说,触发器决定了什么时候一个窗口被计算和输出为窗格(稳定的计算结果),即When的问题。其中最为常见的是基于时间,基于数据到达情况的触发器,基于窗口估计完成度(水位线)的触发器,除此以外也支持用户自定义触发器。
除了控制窗口结果计算何时触发,触发器还提供了三种重定义模式来控制同一窗口的不同窗格关联情况,以规范化How。
- 抛弃: 窗口触发后,窗口内的数据被丢弃,不同窗格之间没有联系。
- 累积: 窗口触发后,窗口内的数据仍被保留在持久化的状态中,而后期的计算结果是对上一次结果的一个修正的版本。
- 累计和撤回: 窗口触发后,在进行累积语义的基础上,计算结果的一份复制也被保留到持久化状态中。当该窗口将来再次触发时(迟到的数据抵达),上一次的结果值先下发做撤回处理,然后将新的结果作为正常数据下发。
其中抛弃模式效率最高,因为不需要维持状态或者过去窗口的数据,但应用场景有限,适合下游实现了累积统计的情况;累积模式与 Lambda 架构十分相似,适用场景广泛,是最常见的模式;累积和撤回模式是最复杂成本最高的模式,需要下游也支持可撤回操作,适合上游操作会导致下游不同的key分布的情况。