OpenMessaging是一个与厂商以及语言无关的,为金融/电子商务/物联网/大数据领域的消息系统和实时数据计算而设计的工业标准。OpenMessaging在去年10月阿里云的云栖大会上宣布进入Linux Foundation引起了不小的关注,然而自此之后便杳无音讯,半年过去gitub repo提交寥寥无几,连specifition都只写了目录,目前来看有点雷声大雨点小的感觉。
尽管OpenMessaging没有得到阿里的足够重视,但是它的使命是值得肯定的。消息中间件作为各个系统之间的桥梁,重要作用之一解耦和连接异构系统,但是由于消息中间件产品缺乏统一的标准或者接口,不同产品间是不兼容的,往往技术选型确定之后就无法迁移,与使用不同消息中间件的系统交互也需要花费很大工夫。另外一点是OpenMessaging是基于云架构设计的,更符合如今一切后端都上云的技术发展趋势。
因此,在架构上OpenMessaging需要归纳出当前主流的系统设计和使用场景,从更为抽象的层面为消息系统的设计和实现提供指引。下面章节分别介绍OpenMessaging的架构设计以及如何应用于使用不同的场景。
领域架构
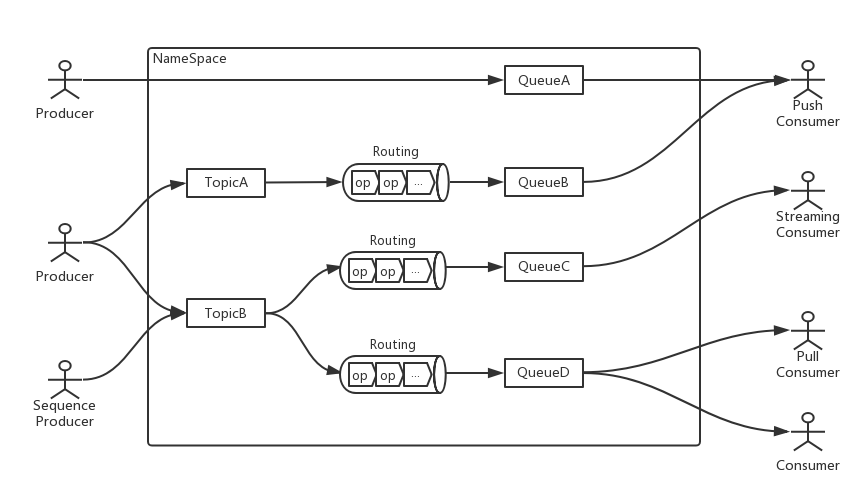
上图展示了OpenMessaging的领域架构。可见不同于普通仅提供管道和存储功能的消息队列,OpenMessaging还具备转换数据的能力(Routing),并且不像Kafka作为附加组件的Streams,OpenMessaging的Routing更多是原生架构的一部分,地位更高。下面逐一解释图中涉及的实体。
NameSpace
NameSpace类似于Linux的cgroup,用于安全地对资源进行隔离。每个NameSpace下都有自己的一组producer, consumer, topic, queue等等。
Producer
OpenMessaging提供两种Producer:
- 普通Producer,为延迟优化,提供多种方法来将消息流式地发送到Topic或者Queue,但是specification并没有进一步描述具体有什么方法,只能拭目以待。
- SequenceProducer,为吞吐量优化,可以将多条消息合并为一个batch再发送给下游。
看起来两种producer并没有什么质的差别,或许最关键的点在于发送方法上的不同。
Consumer
不同于有固定消息模式的消息队列,OpenMessaging提供推、拉和流三种消息模式,分别对应三种consumer:
- PullConsumer,从指定queue拉取消息,可以在任何时候通过消息确认机制提交消费结果。一个PullConsumer只能从一个指定的queue拉取消息。
- PushConsumer,可以从多个queue接受消息,消息是以推的方式从服务端发送过来。PushConsumer可以通过不同的MessageListener来连接多个queue,然后在任何时间通过ReceiveMessageContext来条消费结果。
- StreamingConsumer,一个面向流的consumer,可以很容易地和流式计算/大数据相关的平台集成。StreamingConsumer支持从指定queue像迭代器一样逐条消费消息。
Topic, Queue和Routing
这三个实体有很强的联系,尽管Topic和Queue的作用不同,人们有可能会将它搞混。
Topic
Topic用于存储原始数据,服务端接收到的消息首先会被存放到这里。对于topic是否对消息的分布和顺序提供保证,OpenMessaging未作出要求。
Routing
在topic里面的消息是原始未经处理的,这并不能被consumer直接使用。换句话讲,topic是面向producer的,而不是面向consumer。Routing负责对topic里的消息进行处理,并路由到合适的queue。每个Routing拥有一个operator pipeline,后者由一系列的operator组成。消息经过这个pipeline从topic流向queue。 类似于流计算的一个转换函数,operator代表了对数据进行处理的操作。operator的种类有表达式operator(估计和lambda相似),deduplicatot operator(用于去重),joiner operator,filter operator, rpc operator等等。 最后,Routing可以跨网络传输,即通过建立多个routing实例将消息从一个网络发往另外一个网络。
Queue
消息被路由到queue之后,consumer就可以进行消费了。值得注意的是,Queue是分区的,分区键是消息header的SHARDING_KEY。Queue也可以从producer直接接收消息,即在数据流中跳过Topic和Routing,这样的话延迟更低,适合不需要对消息进行转换的场景。
架构总结
通过Topic和Queue的分离,OpenMessaging将发布和订阅两个过程解耦,再加上用于处理和路由的Routing,使得服务端对于消息流具备更大的灵活性。相对地,producer和consumer的设计则更加轻。以最为熟悉的Kafka作为参照,Kafka producer可以显式指定消息分区或控制分区算法和分区键,在OpenMessaging中这部分功能被放到Routing实现。相似地,Kafka consumer拥有更大的自主权,允许consumer端指定需要读的topic或直接指定要读的topic partition,但在OpenMessaging中consumer是感知不到topic的,需要Routing的配合才可以表达希望消费的数据。
如此瘦客户端胖服务端的设计,虽然导致服务端需要维持更多业务相关的状态,但显然是更加符合OpenMessaging的为云架构设计的理念。更为重要的是,引入Routing作为计算和路由层之后,OpenMessaging较为自然地融合了流式计算,将消息流和实时计算集成为一个整体。
应用场景
P2P

端到端,最为简单的场景,这种情况只涉及到OpenMessaging里的Queue资源,准确来说是只有一个partition的queue。Producer发送消息到queue,然后consumer消费它。
Publish/Subscribe
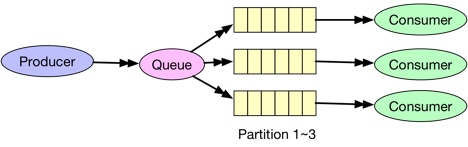
在这个案例中,producer发送消息给多分区的Queue,分区的方式可以是Round-robin或者哈希。这些分区会被指派给订阅了相应queue的consumer。
如果需要的话,可以引入Topic和Routing来增强消息处理能力。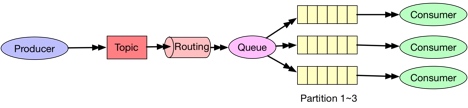
Broadcast
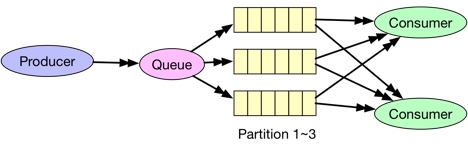
在广播场景下,发送到Queue的消息需要被所有的consumer消费。
Highway

在highway模式下,SequenceProducer唯一关心的是吞吐量,所以个人觉得这条highway更像是大货车的highway,而不是私家车的highway(延迟低)。
Streaming
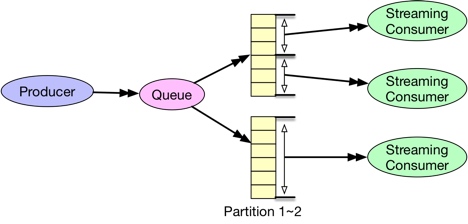
StreamingConsumer就是为这种情况设计的面向流的consumer,可以很容易地和下游的流计算系统集成。
Filter
在大多数的情况下,consumer并不对原始数据感兴趣,而且consumer总希望消费的是经过某些处理的消息,其中最为重要的就是过滤。
如下图所示,Routing模型可以十分方便地实现过滤。在图中,消息会在经过两个filter operator后被路由到queue,该queue需要保存带student标签的并且age属性为18-23的消息。
Online Test

测试对于严谨的系统来说是必不可少的环节,而AB Test等测试方法往往要求线上环境,OpenMessaging可以通过创建一个新的Routing来满足。
Replication
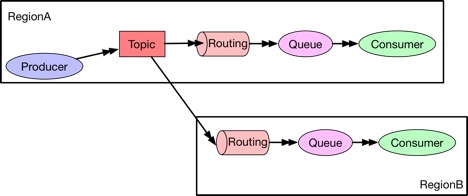
有时候producer和consumer分布在不同的数据中心,OpenMessaging提供了一个简单的方式来将消息从一个地区路由到另外一个地区,即一个topic连接多个routing形成冗余备份。
Upgrade
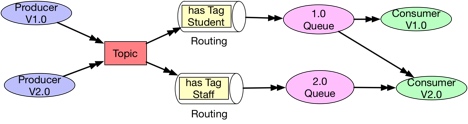
Queue的版本和consumer版本适配,可以通过创建不同版本的queue来同时支持多版本的consumer。
RPC
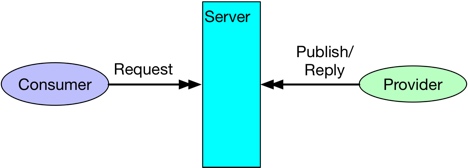
RPC相当于同步消息,即服务端只类似一个blocking queue,producer生产消息后会阻塞,直到consumer确认消费。
应用场景总结
OpenMessaging从需求角度对消息队列的应用场景进行了较为细致的分类和总结,但是由于很多都是一笔带过,其实很多重要的细节并没有讲清楚,比如在P2P场景下partitioning是由Queue负责还是由Producer负责,再比如送达语义要如何保证,这估计也是OpenMessaging一直都停留在0.x版本的原因。
未来展望
根据阿里中间件的博客:
未来一年,OpenMessaging项目将会从开源社区、云平台和生态系统三个维度展开工作.
- 开源社区:推出OpenMessaging的1.0版本,Apache RocketMQ和Apache Pulsar等开源产品会相继实现该标准,同时会尝试推进Spring Cloud,ActiveMQ、RabbitMQ、Kafka等主流平台接入。
- 云平台:RocketMQ的实现会在阿里云的商业消息产品Aliware MQ中落地,成为阿里云平台的上默认消息接入规范,同时也会尝试了解其它云平台的接入意愿。
- 生态系统:OpenMessaging主要会先从三个方面进行生态的延伸和发展。
从用词上可以看出其实阿里也深知将OpenMessaging推广到Kafka等消息中间件的困难,因为对于现已成熟的消息队列来说每个改动影响的范围都非常大,而且OpenMessaging对于注重效率的消息队列来说有些笨重,所以并不看好OpenMessaging在开源社区的发展。
然而在外面过得不好,并不意味着不能“窝里横”。OpenMessaging在阿里内部应该有一定的地位,包括自家的RocketMQ都已经接入了OpenMessaging的alpha版本,还有未来计划成为阿里云的消息接入规范。然而目前阿里云在全球处于第三名的位置,离行业老大AWS还有比较大的差距,因此即使OpenMessaging成为阿里云标准估计也很难为其他云厂商所承认。
尽管前途并不平坦,还是希望OpenMessaging可以至少成长为对消息中间件领域的有启发性意义的一项标准。